
















Noticias IBL | Nueva York
Meta lanzó esta semana Llama 3, con dos modelos: Llama 3 8B, que contiene 8 mil millones de parámetros, y Llama 3 70B, con 70 mil millones de parámetros. (Los modelos con mayor número de parámetros son más capaces que los modelos con menor número de parámetros).
Los modelos de Llama 3 ya están disponibles para descargar y experiencia en meta.ai. Pronto se alojarán en forma administrada en una amplia gama de plataformas en la nube, incluidas AWS, Databricks, Google Cloud, Hugging Face, Kaggle, WatsonX de IBM, Microsoft Azure, NIM de Nvidia y Snowflake. En el futuro, también estarán disponibles versiones de los modelos optimizados para hardware de AMD, AWS, Dell, Intel, Nvidia y Qualcomm.
Llama 3 modelos power Asistente Meta AI de Meta encendido Facebook, Instagram, WhatsApp, Messenger y la web.
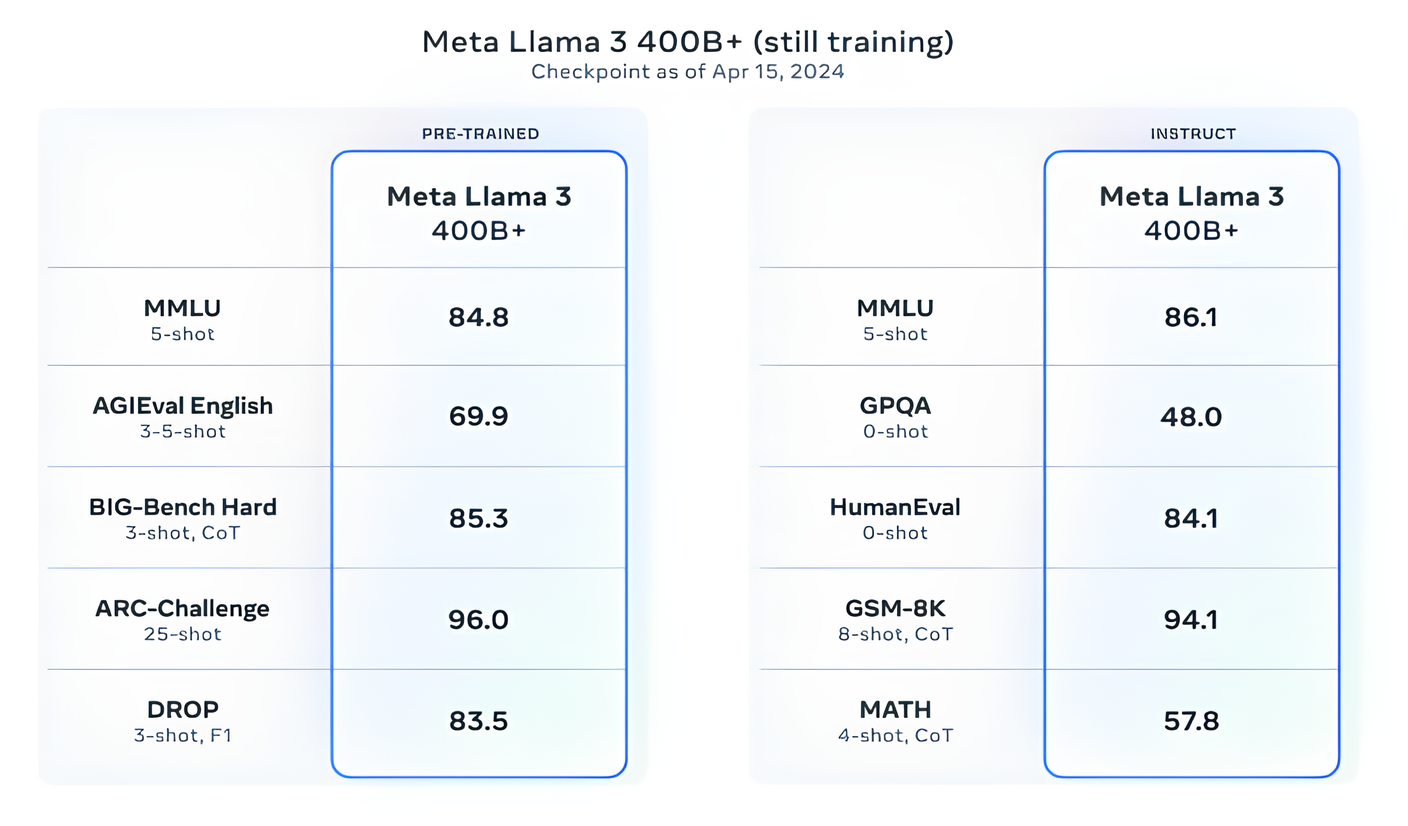
“Nuestro objetivo en el futuro cercano es hacer que Llama 3 sea multilingüe y multimodal, tenga un contexto más amplio y continúe mejorando el rendimiento general en todas las capacidades centrales [modelo de lenguaje grande], como el razonamiento y la codificación”, escribió Meta. en una publicación de blog.

La compañía dijo que estos dos modelos 8B y 70B, entrenados en dos clústeres de 24.000 GPU personalizados, se encuentran entre los modelos de IA generativa de mejor rendimiento disponibles en la actualidad. Para respaldar esta afirmación, Meta señaló las puntuaciones en puntos de referencia de IA populares como MMLU (que intenta medir el conocimiento), ARC (que intenta medir la adquisición de habilidades) y DROP (que prueba el razonamiento de un modelo en fragmentos de texto).
Llama 3 8B supera a otros modelos abiertos como Mistral 7B de Mistral y Gemma 7B de Google, los cuales contienen 7 mil millones de parámetros, en al menos nueve puntos de referencia: MMLU, ARC, DROP, GPQA (un conjunto de biología, física y química). preguntas relacionadas), HumanEval (una prueba de generación de código), GSM-8K (problemas escritos de matemáticas), MATH (otro punto de referencia de matemáticas), AGIEval (un conjunto de pruebas de resolución de problemas) y BIG-Bench Hard (una evaluación de razonamiento de sentido común).

Llama 3 70B supera a Gemini 1.5 Pro en MMLU, HumanEval y GSM-8K y, aunque no rivaliza con el modelo de mayor rendimiento de Anthropic, Claude 3 Opus, Llama 3 70B obtiene una puntuación mejor que el segundo modelo más débil de la serie Claude 3. , Claude 3 Sonnet, sobre cinco puntos de referencia (MMLU, GPQA, HumanEval, GSM-8K y MATH).

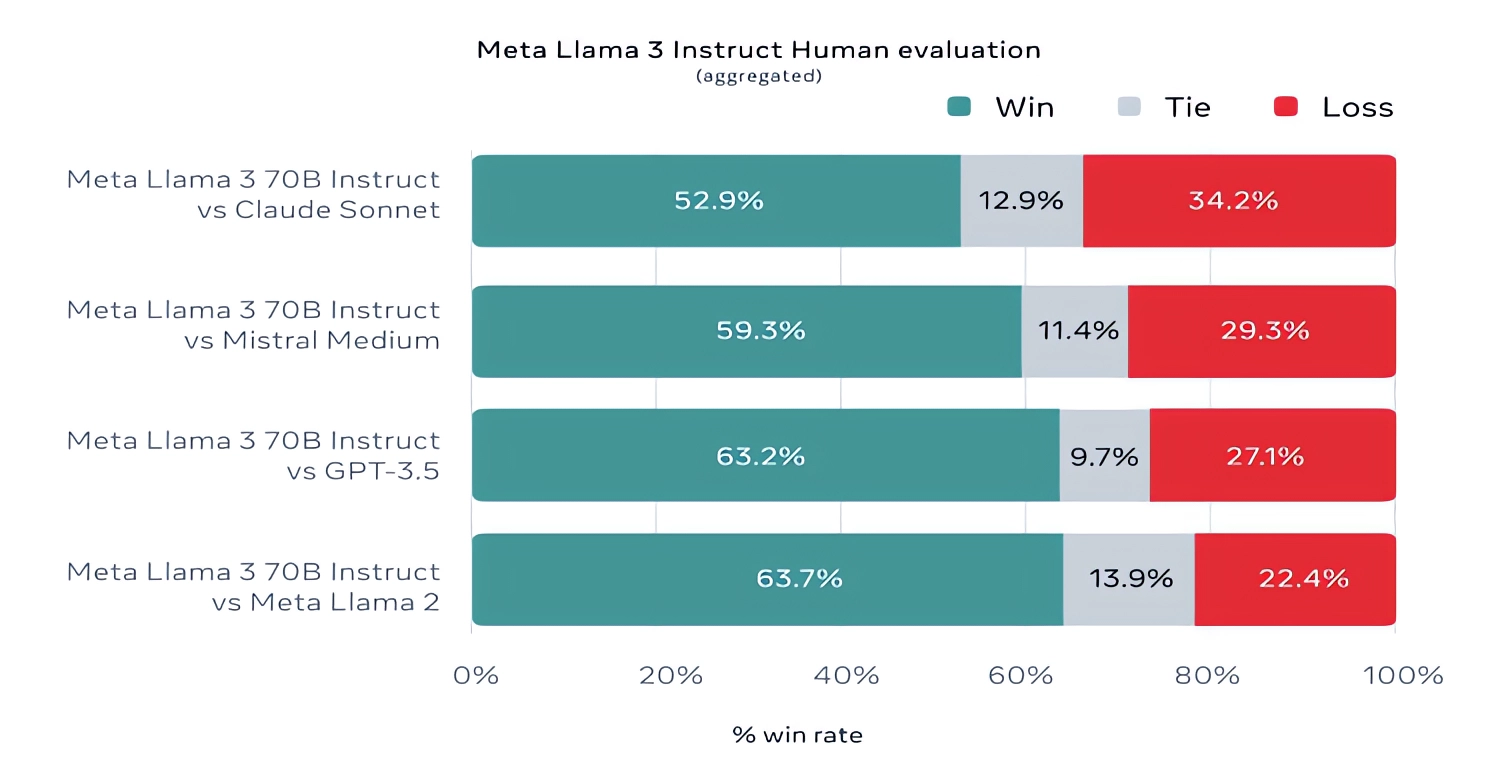
Meta también desarrolló su propio conjunto de pruebas que cubre casos de uso que van desde codificación y escritura creativa hasta razonamiento y resumen. Llama 3 70B se impuso frente al modelo Mistral Medium de Mistral, el GPT-3.5 de OpenAI y Claude Sonnet.
.
Meta Llama 3 es muy bueno, especialmente para un modelo tan pequeño. Podemos incluir un mensaje de varias páginas como nuestro simulador de negociación (https://t.co/j6BcWh4zFb) & es capaz de seguir la complejidad razonablemente bien. No tiene la “inteligencia” de la clase GPT-4, pero aun así es impresionante. pic.twitter.com/qMaRtwogqA
— Ethan Mollick (@emollick) 18 de abril de 2024










