

















IBL News | Nueva York
Investigadores de ByteDance, propietario de TikTok, presentaron una modelo llamada OmniHuman-1 que genera videos deepfake convincentes de manera realista. Sin embargo, la empresa china aún no ha lanzado el sistema.
Para demostrar la calidad de OmniHuman-1, la compañía china publicó ejemplos de una actuación ficticia de Taylor Swift, una charla TED que no tuvo lugar y una conferencia deepfake de Einstein, entre otros [haga clic en la imagen para ver los videos].
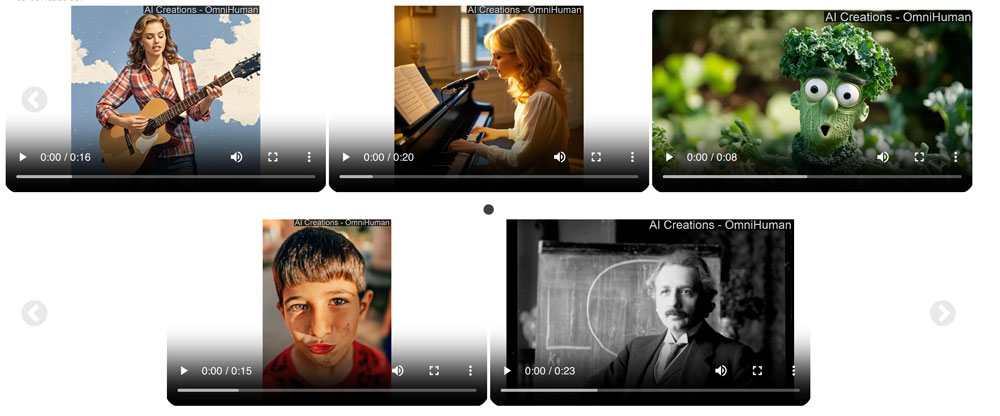
Los investigadores de ByteDance mencionaron que OmniHuman-1 solo necesita una imagen de referencia y audio, como discurso o voz, para generar un clip de longitud arbitraria.
Afirmaron que la relación de aspecto del video de salida y la “proporción corporal” del sujeto, es decir, cuánto de su cuerpo se muestra en las imágenes falsas, son ajustables.
Entrenado en 19,000 horas de contenido de video de fuentes no reveladas, OmniHuman-1 puede editar videos existentes, incluso modificando los movimientos de una persona.










